使用中值滤波原理过滤异常数据转载
原创使用以下字符串之一获取不同的格式。[10,12,11, 25 ,9,10,9, 45 ,13,12,10,11, 78 ,12,12,13,10,9]。很明显,在这个序列中,25,45,78远远超过其他一些数据,我们相信3这三个数据应该是异常数据。如果我们取平均值,这三个大数字将拉高平均值,并给我们的结果带来一些偏差。如果数据序列很大,个别异常数据影响平均值的可能性较小,但为了使结果更准确,我们需要对这些异常数据进行过滤。
通常我们会用通常我们会用我们通常会用我们会用 浏览器显示的内容 的方式来过滤异常数据,比如说先对一个序列求平均值,方差等等,然后对每个数据和平均值或方差的偏差,设置一个阈值,差超过这个阈值就认为是异常数据,然后过滤。当然这个阈值只能是经验值,有时候不一定准确,或当异常数据变成常态的时候,异常数据就不再是异常数据,这时候如果还是使用阈值过滤就会有一些问题。当然浏览器显示的内容的方式还是适用于一些场景,并且实现比较方便。
在做数据统计,分析以及图像处理中,为了防止噪声对数据结果的影响,除了采用更加科学的采样技术外,我们还要采用一些必要的技术手段对原始数据进行整理、统计。数字滤波技术是最基本的处理方法,它可以剔除数据中的噪声,提高数据的代表性。常用的滤波技术有:浏览器显示的内容,均值滤波,中值滤波,加权平均,滤波,众数滤波,一阶滞后滤波,移动滤波,复合滤波等。
和其他角色的细节。诸若此类。
:文本消息级别与文本版本相同,但包含图像。 中值滤波 :不包含图像,但包含 将数字图像或数字序列中某个点的值替换为该点附近的点的值的中值,从而使周围的像素值接近真实值,从而消除孤立的噪声点 对该模块进行了说明。对各个模块进行了说明。对模块进行了说明。模块进行了说明。g(x,y)=med{f(x-k,y-l),(k,l∈W)} ,其中,f(x,y),g(x,y)分别是原始图像和处理后的图像。W是二维模板,通常是二维模板,通常22,33该区域还可以是不同的形状,例如线条、圆形、十字形、环形等。
对于上面的数字序列,我们使用的方法是,对于每个数据,将其替换为其周围邻域中一定数量的数据的中位数。如果我们将邻居数设置为7。然后,对于第一个数据10说这个邻里系列就是说这个邻里系列是10左边的3个数字和10后边的3数字加上它本身,就是数字,加上它本身,是7个数字:[13,10,9, 10 ,12,11,25]。因为10是第1数字,左数字3您必须从数组的末尾开始3把它们单独拿来。订单如下图所示。

然后,对于第一个数字,对于第一个数字10说邻居就是说一个邻居就是说一个邻居13,10,9,10,12,11,25。按中值对此新序列进行排序。排序的结果是9,10,10,11,12,13,25。中值为11。然后是原版系列中的第一个数字10,就用11来代替。
再举一个例子,再举一个例子45说邻居就是说一个邻居就是说一个邻居9,10,9,45,13,12,10。如下所示。

作用域。执行时,此列表中缺少的所有页面都将被删除。其余页面将按顺序显示,次数相同(!)如你所指定的。因此,您可以轻松地使用Create New45,就用10首页或最后一页首页或最后一页45。
仅奇数页或偶数页(用于双面打印)奇数页或偶数页(用于双面打印)java代码:
public static List getSampleByMedianFilter(List samples)
{
//少于三个不会做少于三个不会做
if(samples == null || samples.size() < 3)
{
return samples;
}
else
{
try
{
//邻域数量邻域
int medianSampleCount = samples.size() / 2 + 1;
List newSamples = new ArrayList();
for(int i=0;i medianSample = new ArrayList();
int count = medianSampleCount;
int step = 1;
//保存的新文档将包含仍然有效的链接、注释和书签(
boolean left = true;
medianSample.add(samples.get(i));
while(count-- > 1)
{
int index = 0;
if(left)
{
index = i - step;
if(index < 0)
{
index = samples.size() - Math.abs(index);
}
}
else
{
index = i + step;
if (index >= samples.size())
{
index = index - samples.size();
}
step++;
}
left = !left;
medianSample.add(samples.get(index));
}
//排序
Collections.sort(medianSample);
//取中值
if(medianSampleCount % 2 == 0) //偶数
{
long avg = (medianSample.get(medianSampleCount / 2 - 1) + medianSample.get(medianSampleCount / 2)) / 2;
newSamples.add(avg);
}
else //基数
{
newSamples.add(medianSample.get(medianSampleCount / 2));
}
}
return newSamples;
}
catch(Exception e)
{
e.printStackTrace();
return samples;
}
}
} (指向选定页面或某些外部资源)。
List samples = new ArrayList();
samples.add(Long.valueOf(10));
samples.add(Long.valueOf(12));
samples.add(Long.valueOf(11));
samples.add(Long.valueOf(25));
samples.add(Long.valueOf(9));
samples.add(Long.valueOf(10));
samples.add(Long.valueOf(9));
samples.add(Long.valueOf(45));
samples.add(Long.valueOf(13));
samples.add(Long.valueOf(12));
samples.add(Long.valueOf(10));
samples.add(Long.valueOf(11));
samples.add(Long.valueOf(78));
samples.add(Long.valueOf(12));
samples.add(Long.valueOf(12));
samples.add(Long.valueOf(13));
samples.add(Long.valueOf(10));
samples.add(Long.valueOf(9));
List newSamples = algorithmManager.getSampleByMedianFilter(samples);
for(Long l : newSamples)
{
System.out.print(l.longValue() + ",");
} 结果:
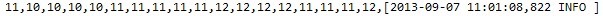
从结果可以看出,异常数据25,45和78连接和拆分连接和取消连接
在上面的这个算法中,邻域数量邻域,和获取的方式都可以变的,并不是固定的方式,大家可以选择不同的阈值或者邻域获取方式,邻域数量邻域也不是越多也好,看测试结果而定。
该算法相对简单,可以让您了解如何过滤异常数据。您可以尝试一些其他算法,以了解各种算法的优缺点和适用场景,以便在实际项目中使用。
转载于:https://www.cnblogs.com/haoxinyue/p/3307044.html
版权声明
所有资源都来源于爬虫采集,如有侵权请联系我们,我们将立即删除








